# 概述
# 基本信息
- 标题:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- 《NeRF: 将场景表示为用于视图合成的神经辐射场》
- 作者:
- Ben Mildenhall*(UC Berkeley)
- Pratul P. Srinivasan*(UC Berkeley)
- Matthew Tancik*(UC Berkeley)
- Jonathan T. Barron(Google Research)
- Ravi Ramamoorthi(UC San Diego)
- Ren Ng(UC Berkeley)
- GitHub 仓库
- 官网
# 核心
非显式地将一个复杂的静态场景用一个神经网络来建模,
-
在网络训练完成后,可以从任意角度渲染出清晰的场景图片
-
用一个 MLP 神经网络去隐式地学习一个静态 3D 场景
-
基于训练好的神经网络,即可以从任意角度渲染出图片结果了
-
训练 MLP 的条件:针对一个静态场景,需要提供大量 **【相机参数已知】** 的图片。
# 理解重点
理解 NeRF 是如何从一系列 2D 图像中学习到 3D 场景,又是如何渲染出 2D 图像
- 如何用 NeRF 来表示 3D 场景?
- 如何基于 NeRF 渲染出 2D 图像?
- 如何训练 NeRF?
# 重点内容
# Abstract 摘要
# 原文对照
Abstract.
We present a method that achieves state-of-the-art results for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
我们提出了一种,通过使用稀疏的输入视图集来优化底层的连续体积场景函数,从而获得用于合成复杂场景的新视图的最先进的结果。
Our algorithm represents a scene using a fully-connected (nonconvolutional) deep network, whose input is a single continuous 5D coordinate (spatial location (x, y, z) and viewing direction (θ, φ)) and whose output is the volume density and view-dependent emitted radiance at that spatial location.
我们的算法使用完全连通 (非卷积) 的深度网络来表示场景,其输入是单个连续的 5D 坐标 (空间位置 (x,y,z) 和观察方向 (θ,φ)),其输出是该空间位置的体积密度和依赖于视图的发射辐射。
We synthesize views by querying 5D coordinates along camera rays and use classic volume rendering techniques to project the output colors and densities into an image.
我们通过查询相机光线上的 5D 坐标来合成视图,并使用经典的体绘制技术将输出的颜色和密度投影到图像中。
Because volume rendering is naturally differentiable, the only input required to optimize our representation is a set of images with known camera poses.
由于体积渲染是自然可分化的,因此唯一需要优化的输入表示 是一组具有已知相机姿态的图像。
We describe how to effectively optimize neural radiance fields to render photorealistic novel views of scenes with complicated geometry and appearance, and demonstrate results that outperform prior work on neural rendering and view synthesis.
我们描述了如何有效地优化神经辐射场,以渲染具有复杂几何形状和外观的场景的光逼真新颖视图,并展示了优于先前神经渲染和视图合成工作的结果。
View synthesis results are best viewed as videos, so we urge readers to view our supplementary video for convincing comparisons.
视图合成结果最好以视频的形式观看,所以我们力荐读者们观看我们为了证明对比所外加的视频。
# 总结
-
本文的主要工作:
1
2
3提出了一种方法:合成复杂场景的新视图
神经网络MLP:全连接的非卷积深度网络
输入:一组具有已知【相机姿态】的图像(【相机姿态】:空间位置、观察方向) -
重点问题
1
2
3用神经辐射场来表示场景
如何从NeRF渲染出图片?——基于辐射场的体素渲染算法
NERF的训练过程
# 重点问题讨论
# 用神经辐射场来表示场景
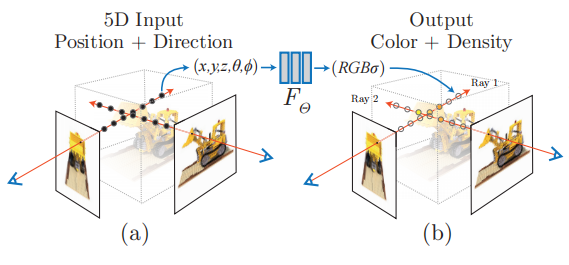
NeRF 函数是将一个连续的场景表示为一个输入为 5D 向量的函数,包括一个空间点的 3D 坐标位置 ,以及视角方向
。这个神经网络可以写作:
输出结果中, 是对应 3D 位置(或者说是体素)的密度,而
是视角相关的该 3D 点颜色。在具体的实现中,
首先输入到 MLP 网络中,并输出
和中间特征,中间特征和
再输入到额外的全连接层中并预测颜色。因此,体素密度只和空间位置有关,而颜色则与空间位置以及观察的视角都有关系。基于 view dependent 的颜色预测,能够得到不同视角下不同的光照效果,非常惊艳。可以看出,NeRF 函数的表示非常简单。
# 如何从 NeRF 渲染出图片?—— 基于辐射场的体素渲染算法
NeRF 函数得到的是一个 3D 空间点的颜色和密度信息,但当用一个相机去对这个场景成像时,所得到的 2D 图像上的一个像素实际上对应了一条从相机出发的射线上的所有连续空间点。我们需要通过渲染算法从这条射线上的所有点得到这条射线的最终渲染颜色。同时,为了保证网络可以训练,NeRF 中需要采用可微的渲染方法。
*1. 经典的 volume rendering 方式 *
论文中首先介绍了经典的体素渲染 volume rendering [2] 方法。体素密度 可以被理解为,一条射线
在经过
处的一个无穷小的粒子时被终止的概率,这个概率是可微的。换句话说,有点类似于这个点的不透明度。由于一条射线上的点是连续的,自然的想法是这条射线的颜色可以由积分的方式得到。将一个相机射线标记为
,这里
是射线原点,
是前述的相机射线角度,t 的近段和远端边界分别为
以及
。那么这条射线的颜色,则可以用积分的方式表示为:
此处, 是射线从
到
这一段路径上的累积透明度,可以被理解为这条射线从
到
一路上没有击中任何粒子的概率。其具体的形式为:
但是,实际应用中,我们并不可能够用 NeRF 去估计连续的 3D 点的信息,因此就需要数值近似的方法。这里也是 NeRF 中非常核心的一个部分。
# NeRF 的训练过程
介绍完 NeRF 的基本原理,论文接下来介绍了 NeRF 中的两个重要 Trick,以及训练方式。
*1. 训练高质量 NeRF 的重要技巧 —— 位置信息编码 *
NeRF 函数的输入为位置和角度信息,作者发现直接将位置和角度作为网络的输入得到的结果是相对模糊的(见实验部分)。而用 positon encoding 的方式将位置信息映射到高频则能有效提升清晰度效果。具体而言,这里采用的是与 Transformer 中类似的正余弦周期函数的形式。我的理解是,采用 position encoding 能够使得网络更容易的理解并建模位置信息。
*2. 训练高质量 NeRF 的重要技巧 —— 多层级体素采样 *
NeRF 的渲染过程计算量很大,每条射线都要采样很多点。但实际上,一条射线上的大部分区域都是空区域,或者是被遮挡的区域,对最终的颜色没有啥贡献。因此,作者采用了一种 “coarse to fine" 的形式,同时优化 coarse 网络和 fine 网络。这一部分也非常有趣。首先对于 coarse 网络,我们可以采样较为稀疏的 个点,并将前述的离散求和函数重新表示为:
,其中
接下来,可以对 做归一化
此处的 可以看作是沿着射线的概率密度函数(PDF),如下图所示。通过这个概率密度函数,我们可以粗略地得到射线上物体的分布情况。
接下来,基于得到的概率密度函数来采样 个点,并用这
个点和前面的
个点一同计算 fine 网络的渲染结果
。虽然 coarse to fine 是计算机视觉领域中常见的一个思路,但这篇方法中用 coarse 网络来生成概率密度函数,再基于概率密度函数采样更精细的点算的上是很有趣新颖的做法了。二阶段的采样示意图如下所示:
*3. 损失函数与一些训练细节 *
最后,训练损失的定义倒是非常简单,直接定义在渲染结果上的 L2 损失 (同时优化 coarse 和 fine):
训练时长方面,论文中提及的速度是一个场景要用单卡 V100 训练 1-2 天左右。